
대표적인 데이터 구조6: 해쉬 테이블 (Hash Table)
1. 해쉬 구조
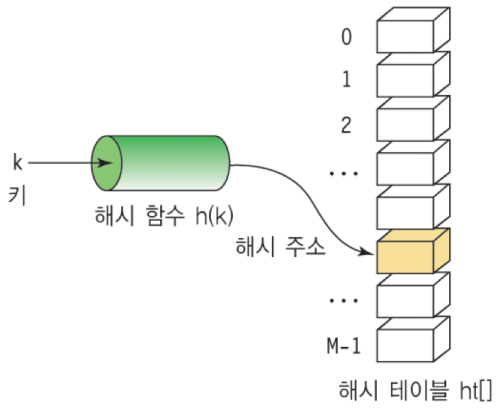
- Hash Table: 키(Key)에 데이터(Value)를 저장하는 데이터 구조
- Key를 통해 바로 데이터를 받아올 수 있으므로, 속도가 획기적으로 빨라짐
- 파이썬 딕셔너리(Dictionary) 타입이 해쉬 테이블의 예: Key를 가지고 바로 데이터(Value)를 꺼냄
- 보통 배열로 미리 Hash Table 사이즈만큼 생성 후에 사용 (공간과 탐색 시간을 맞바꾸는 기법)
- 단, 파이썬에서는 해쉬를 별도 구현할 이유가 없음 - 딕셔너리 타입을 사용하면 됨
2. 알아둘 용어
- 해쉬(Hash): 임의 값을 고정 길이로 변환하는 것
- 해쉬 테이블(Hash Table): 키 값의 연산에 의해 직접 접근이 가능한 데이터 구조
- 해싱 함수(Hashing Function): Key에 대해 산술 연산을 이용해 데이터 위치를 찾을 수 있는 함수
- 해쉬 값(Hash Value) 또는 해쉬 주소(Hash Address): Key를 해싱 함수로 연산해서, 해쉬 값을 알아내고, 이를 기반으로 해쉬 테이블에서 해당 Key에 대한 데이터 위치를 일관성있게 찾을 수 있음
- 슬롯(Slot): 한 개의 데이터를 저장할 수 있는 공간
- 저장할 데이터에 대해 Key를 추출할 수 있는 별도 함수도 존재할 수 있음
3. 간단한 해쉬 예
hash_table = list([i for i in range(10)])
hash_table
Result : [0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
def hash_func(key):
return key % 5
3.3. 해쉬 테이블에 저장해보겠습니다.
- 데이터에 따라 필요시 key 생성 방법 정의가 필요함
data1 = 'Andy'
data2 = 'Dave'
data3 = 'Trump'
data4 = 'Anthor'
## ord(): 문자의 ASCII(아스키)코드 리턴
print (ord(data1[0]), ord(data2[0]), ord(data3[0]))
print (ord(data1[0]), hash_func(ord(data1[0])))
print (ord(data1[0]), ord(data4[0]))
- 3.3.2. 해쉬 테이블에 값 저장 예
- data:value 와 같이 data 와 value를 넣으면, 해당 data에 대한 key를 찾아서, 해당 key에 대응하는 해쉬주소에 value를 저장하는 예
def storage_data(data, value):
key = ord(data[0])
hash_address = hash_func(key)
hash_table[hash_address] = value
3.4. 해쉬 테이블에서 특정 주소의 데이터를 가져오는 함수도 만들어봅니다.
storage_data('Andy', '01055553333')
storage_data('Dave', '01044443333')
storage_data('Trump', '01022223333')
3.5. 실제 데이터를 저장하고, 읽어보겠습니다.
def get_data(data):
key = ord(data[0])
hash_address = hash_func(key)
return hash_table[hash_address]
get_data('Andy')
Result : ‘01055553333’
- 장점
- 데이터 저장/읽기 속도가 빠르다. ( 검색 속도가 빠르다 )
- 해쉬는 키에 대한 데이터가 있는지 확인이 쉽다. ( 중복 )
- 단점
- 일반적으로 저장공간이 좀 더 많이 필요하다.
- 여러 키에 해당하는 주소가 동일할 경우, 충돌을 해결하기 위한 별도 자료 구조가 필요하다. ( 동일 참조 )
- 주요 용도
- 검색이 많이 필요한 경우
- 저장, 삭제, 읽기가 빈번한 경우
- 캐쉬 구현시 ( 중복 확인이 쉽기 때문 )
충돌 해결 알고리즘 ( 좋은 해쉬 함수 사용하기 )
- 해쉬 테이블의 가장 큰 문제는 충돌 (collision) 의 경우이다. 이 문제를 충돌/ 해쉬 충돌이라고 부른다.
Chaining 기법
- Open hashing 기법 중 하나 : 해쉬 테이블 저장 공간 외의 공간을 활용하는 기법
- 충돌이 나면, 링크드 리스트 라는 자료 구조를 사용해서, 링크드 리스트로 데이터를 추로 뒤에 연결시켜 저장하는 기법이다.
hash_table = list([0 for i in range(8)])
def get_key(data):
return hash(data)
def hash_function(key):
return key % 8
def save_data(data, value):
# get_key 함수를통해 index_key 를 가져옴
index_key = get_key(data)
# index_key 에서 hash_function 으로 hash_address 를 가져옴
hash_address = hash_function(index_key)
# hash_table[hash_address] 안에 값이 0이 아니면,
# 안에 값이 있는 것이므로, 링크드 리스트 형태로 배열을 다시 만들어 바로 뒤쪽 인덱스로 넣어준다.
if hash_table[hash_address] != 0:
for index in range(len(hash_table[hash_address])):
if hash_table[hash_address][index][0] == index_key:
hash_table[hash_address][index][1] = value
return
hash_table[hash_address].append([index_key, value])
else:
# hash_table[hash_address] 값이 0일 경우 배열을 만들고 index_key 와 value 배열을 테이블에 넣어준다.
hash_table[hash_address] = [[index_key, value]]
def read_data(data):
index_key = get_key(data)
hash_address = hash_function(index_key)
if hash_table[hash_address] != 0:
for index in range(len(hash_table[hash_address])):
if hash_table[hash_address][index][0] == index_key:
return hash_table[hash_address][index][1]
return None
else:
return None